主要面向的问题
- 半监督聚类方法通过随机选取成对约束来提高性能,这可能导致冗余和不稳定性。在这种情况下,主动聚类通过有效的使用成对约束来最大限度的提高注释的效率。
- 主动学习现有的方法缺乏对查询条件的全面考虑,并且重复运行半监督聚类来更新标签。
主要的方法
主动密度峰值聚类
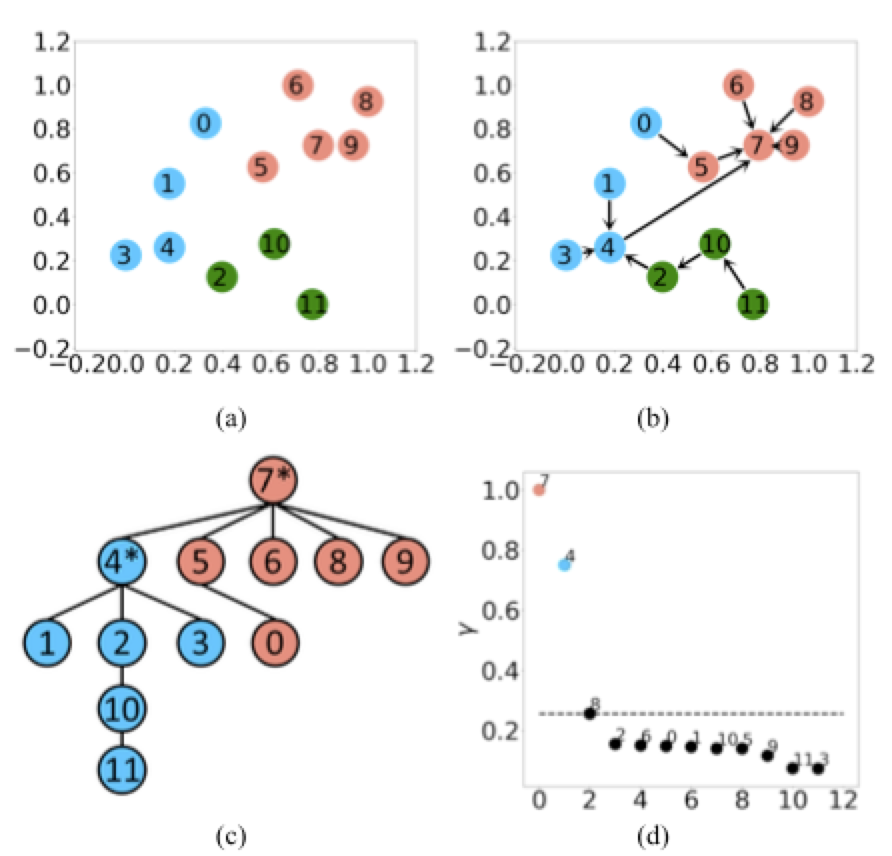
在初始化阶段,测量对象$x_{i}$成为簇中心的概率,并采用多叉树表示成对对象$x_{i}$之间的关系。
在静态选择阶段,通过查询具有代表性的对象$x_{i}$来构造初始领域,从而捕获聚类的模式。
在动态选择阶段,通过迭代的查询具有最大局部不确定性的信息对象$x_{i}$,并通过一个快速更新策略(FUS)更新标签。
初始化
(a)计算局部密度 $ρ$
(b)最小化距离 $δ_i$
(c)描述树
(d)量化程度$γ_i$静态代表实例选择
虽然决策图可以识别出具有代表性的实例,但这种方法有两个局限性:
1)必须绘制决策图,人为地选择转折点;
2)选择的聚类中心可能不正确。为了解决这些问题,我们首先利用滑动窗口来自动识别转折点。然后,查询潜在的聚类中心,构造一个初始邻域集。
flow st=>start: 滑动窗口 op=>operation: 潜在聚类中心ρ op1=>operation: 问询过程 op3=>end: 初始化社区N st(right)->op(right)->op1(right)->op3(right) &



